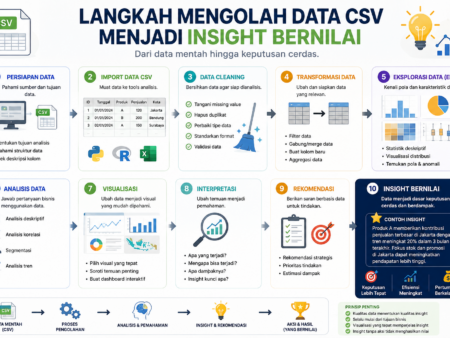
Jelajahi bagaimana Apache Spark menjadi solusi unggul dalam pengolahan data besar, menawarkan kecepatan tinggi dan kemampuan pemrosesan yang efisien untuk berbagai aplikasi analisis data.
Pengolahan Data Besar dengan Apache Spark

Daftar Isi
Pengertian Apache Spark
Apache Spark adalah framework open-source yang dirancang untuk pemrosesan data besar (big data) secara cepat dan efisien. Dengan kemampuan untuk memproses data dalam memori, Spark menawarkan kecepatan yang jauh lebih tinggi dibandingkan dengan sistem pemrosesan data tradisional seperti Hadoop MapReduce. Spark mendukung berbagai bahasa pemrograman, termasuk Scala, Java, Python, dan R, sehingga memudahkan pengembang untuk bekerja dengan data besar.
Fitur Utama Apache Spark
1. Pemrosesan Data dalam Memori
Spark menyimpan data dalam memori, yang memungkinkan akses yang lebih cepat dibandingkan dengan pemrosesan berbasis disk. Ini sangat berguna untuk aplikasi yang memerlukan analisis data secara real-time.
2. API yang Mudah Digunakan
Apache Spark menyediakan API yang sederhana dan intuitif, sehingga memungkinkan pengembang untuk dengan mudah menulis aplikasi pemrosesan data tanpa harus memahami kompleksitas di baliknya.
3. Dukungan untuk Berbagai Sumber Data
Apache Spark dapat terhubung dengan berbagai sumber data, seperti HDFS, Apache Cassandra, Apache HBase, dan Amazon S3. Ini memudahkan integrasi dengan berbagai sistem penyimpanan data.
4. Kemampuan untuk Menangani Berbagai Jenis Pemrosesan
Spark mendukung berbagai jenis pemrosesan, termasuk batch processing, stream processing, dan interaktif querying. Ini membuatnya sangat fleksibel untuk berbagai kebutuhan analisis data.
Keuntungan Penggunaan Apache Spark
1. Kecepatan
Dengan pemrosesan data dalam memori, Apache Spark dapat memproses data jauh lebih cepat dibandingkan dengan sistem tradisional, membuatnya ideal untuk aplikasi yang memerlukan analisis cepat.
2. Skalabilitas
Apache Spark dirancang untuk dapat diskalakan dengan mudah. Pengguna dapat menambahkan lebih banyak node ke cluster untuk meningkatkan kapasitas pemrosesan tanpa memerlukan perubahan signifikan pada aplikasi yang ada.
3. Komunitas yang Besar
Apache Spark memiliki komunitas pengguna dan pengembang yang besar dan aktif. Ini berarti ada banyak sumber daya, dokumentasi, dan dukungan yang tersedia untuk membantu pengguna baru.
Aplikasi Apache Spark
Apache Spark digunakan dalam berbagai aplikasi, termasuk analisis data, machine learning, pemrosesan stream, dan pengolahan data besar. Beberapa contoh aplikasi nyata termasuk:
- Analisis data keuangan untuk mendeteksi penipuan.
- Rekomendasi produk dalam e-commerce.
- Analisis log untuk pemantauan sistem.
- Pemrosesan data sensor dalam Internet of Things (IoT).
Kesimpulan
Apache Spark adalah alat yang sangat kuat untuk pengolahan data besar, menawarkan kecepatan, skalabilitas, dan kemudahan penggunaan. Dengan berbagai fitur dan aplikasi yang luas, Spark menjadi pilihan utama bagi banyak organisasi yang ingin memanfaatkan data besar untuk mendapatkan wawasan yang lebih baik dan membuat keputusan yang lebih informasional. Dengan dukungan komunitas yang besar, Apache Spark terus berkembang dan menjadi solusi yang semakin relevan dalam era big data saat ini.